Most teams celebrate when they get the pipeline working. The real work starts after that.
There is a moment in almost every DevOps journey that feels like arrival. The CI/CD pipeline is running. Deployments are automated. Infrastructure is provisioned through code. The team stops doing things manually that they used to do manually, and it feels like a significant achievement — because it is.
But automation is not the destination. It is the starting point.
The teams that get the most out of DevOps are not the ones who automated the most things. They are the ones who figured out what to do after the automation was in place — how to measure it, improve it, and align it with actual business outcomes rather than technical metrics.
That transition, from automation to optimisation, is what DevOps maturity actually looks like in practice. And it is where most teams stall.
Why automation alone is not enough
Automation solves a specific category of problem. It removes manual steps, reduces human error, increases repeatability, and speeds up processes that were previously slow because a person had to do them by hand.
These are genuine improvements. But they are improvements to efficiency — not necessarily to effectiveness.
A team can have a fully automated pipeline that deploys broken code faster than ever before. They can have infrastructure as code that provisions environments consistently — consistently wrong. They can have automated testing that runs on every commit but covers the wrong things and misses the failures that actually matter.
Automation amplifies what you already have. If the underlying processes, decisions, and feedback loops are sound, automation makes them faster and more reliable. If they are not sound, automation makes the problems happen at greater speed and scale.
This is why maturity is not measured by how much you have automated. It is measured by how well your entire system — people, processes, tools, and feedback — works together to deliver value reliably and improve continuously.
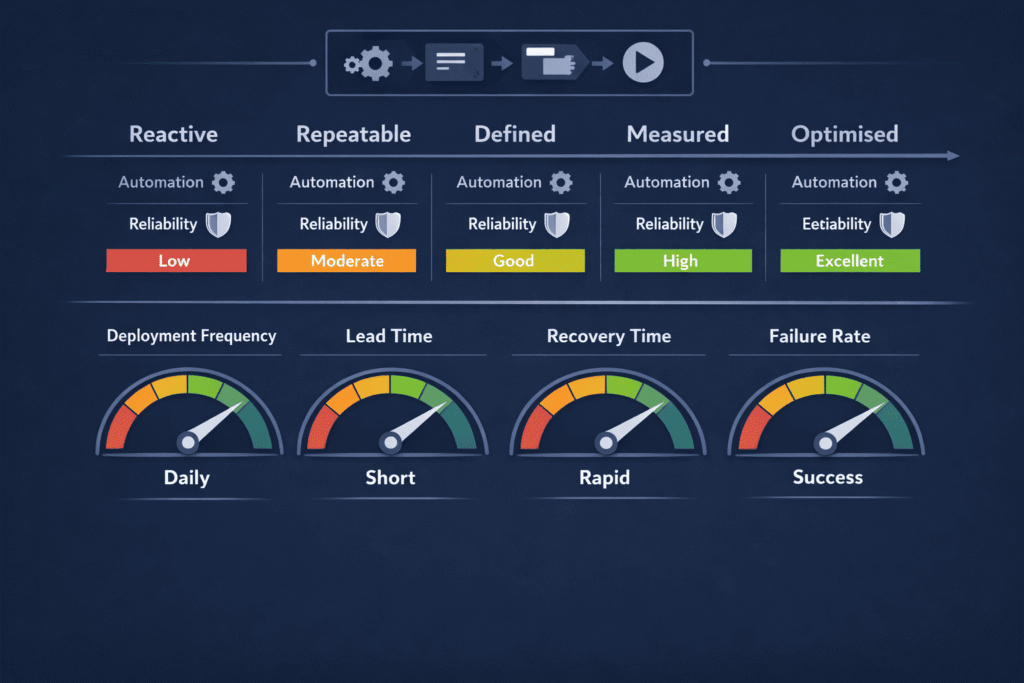
The DevOps maturity stages in practice
DevOps maturity is not a linear path from bad to good. It is a progression through increasingly sophisticated ways of thinking about software delivery. Most frameworks describe four or five stages. In practice, they look something like this.
Stage 1 — Reactive
Everything is manual. Deployments are events. Something breaks, someone fixes it. There is no pipeline, no shared tooling, no consistent process. Development and operations are separate teams with separate goals and separate problems. This is where most organisations start and where the pain of the status quo eventually forces change.
Stage 2 — Repeatable
The team has started automating. There is a build process. There may be a basic CI pipeline. Deployments are more consistent. But the automation is fragile — it works when conditions are right and breaks when they are not. The pipeline is a single developer’s creation that only that developer fully understands. Documentation is sparse. The process works but it is not resilient.
Stage 3 — Defined
Automation is stable and documented. The CI/CD pipeline is a shared team asset rather than an individual’s project. Infrastructure is provisioned through code. Testing is automated and integrated into the pipeline. There are standards — for branching, for environments, for deployment procedures. This is the stage most people mean when they say a team “has DevOps.” It is a solid foundation. It is not maturity.
Stage 4 — Measured
This is where the shift from automation to optimisation begins. The team is not just running the pipeline — they are measuring it. Deployment frequency, lead time for changes, mean time to recovery, change failure rate. These four metrics — popularised by the DORA research programme — give the team an objective view of how the delivery system is actually performing. Decisions about process improvements are driven by data rather than intuition or preference.
Stage 5 — Optimised
The delivery system is continuously improving based on what the measurements reveal. Bottlenecks are identified and addressed. Feedback loops are short. The team experiments with process changes and measures the impact. Security, compliance, and cost are built into the pipeline rather than added after. The entire system — from code commit to production — is understood as a single value stream and optimised as one.
The four DORA metrics and why they matter
If there is one framework worth understanding for DevOps maturity, it is the DORA metrics. They emerged from years of research into what separates high-performing software delivery teams from low-performing ones, and they measure four things:
Deployment frequency — how often the team successfully deploys to production. High performers deploy multiple times per day. Low performers deploy once a month or less. Frequency is a proxy for how small and safe the team’s changes are.
Lead time for changes — how long it takes from a code commit to that code running in production. High performers measure this in hours. Low performers measure it in weeks or months. Lead time reveals how much friction exists in the delivery pipeline.
Mean time to recovery — how long it takes to restore service after a production incident. High performers recover in under an hour. Low performers take days. Recovery time reflects the quality of monitoring, alerting, and incident response processes.
Change failure rate — what percentage of deployments cause a failure requiring remediation. High performers see failure rates below 15 percent. This metric reveals the quality of testing, code review, and deployment practices.
These four metrics matter because they are outcome-focused rather than activity-focused. They do not measure how many pipelines you have built or how many steps you have automated. They measure whether the system is actually delivering value reliably and recovering quickly when it does not.
A team that has all four metrics trending in the right direction is a team that is genuinely optimising — not just automating.
Where most teams stall — and why
The jump from Stage 3 to Stage 4 is where most DevOps initiatives plateau. The automation is working. Things are better than they were. The pressure to improve further is less acute because the most painful problems have been solved.
But there are predictable patterns that keep teams stuck at the automation stage.
Measuring the wrong things
Teams measure what is easy to measure rather than what matters. Pipeline run time. Number of builds per day. Test coverage percentage. These are activity metrics — they tell you what the system is doing, not whether it is delivering value. A pipeline that runs in four minutes and deploys broken code twice a day is worse than one that runs in twelve minutes and deploys working code reliably.
Treating DevOps as a tooling problem
Maturity is not achieved by adding more tools. It is achieved by improving how people work together across the entire delivery system. A team that resolves every friction point by adding another tool ends up with a complex toolchain that nobody fully understands and that creates its own friction. The tool should serve the process — not define it.
Siloed ownership of the pipeline
When the pipeline is owned by a platform team or a single DevOps engineer, the rest of the team treats it as infrastructure they consume rather than a system they are responsible for improving. Maturity requires the entire team — developers, testers, operations, security — to feel ownership over the delivery process and to actively contribute to improving it.
Skipping the feedback loop
Automation without feedback is a one-way system. Optimisation requires closing the loop — measuring what happens after deployment, feeding that information back into development decisions, and using production data to guide what gets built and how it gets delivered. Teams that do not instrument their applications and infrastructure are flying blind no matter how sophisticated their pipeline is.
Neglecting the human side
DevOps maturity is as much a cultural achievement as a technical one. A team that has the right tools but the wrong incentives — where developers are rewarded for shipping features and operations teams are rewarded for stability, with no shared accountability for delivery outcomes — will not reach maturity regardless of the automation in place.
What optimisation actually looks like day to day
Optimisation is not a project with a start and end date. It is a set of practices that become part of how the team works continuously.
Short feedback loops at every stage
Every stage of the delivery process should provide fast, clear feedback. A developer should know within minutes whether their commit broke something. A deployment should trigger automatic validation. A production issue should surface an alert before a user reports it. The shorter the feedback loop, the smaller and cheaper the corrections.
Continuous improvement as a team habit
High-maturity teams hold regular retrospectives specifically focused on the delivery process — not just the product. What slowed us down this sprint? Where did we lose time in the pipeline? What caused the incident last week and how do we prevent the next one? These conversations, held consistently, compound into significant improvements over time.
Shifting security and quality left
Optimised teams do not add security scanning and quality checks at the end of the pipeline. They build them in from the start — linting and static analysis on every commit, dependency vulnerability scanning in the build stage, security testing integrated before deployment. The earlier a problem is caught, the cheaper it is to fix.
Cost and resource optimisation
At higher maturity levels, optimisation extends beyond the delivery process itself into the infrastructure it runs on. Cloud cost monitoring, right-sizing of resources, auto-scaling policies tuned to actual traffic patterns, and elimination of idle environments are all part of an optimised DevOps practice. The pipeline does not just deliver software efficiently — it delivers it economically.
Chaos engineering and resilience testing
Mature teams do not wait for production failures to discover weaknesses. They introduce controlled failures in non-production environments to test how the system responds. This practice — chaos engineering — builds confidence in the system’s resilience and surfaces failure modes before they become incidents.
A practical path forward for teams at Stage 3
If your team has solid automation in place but is not yet measuring and optimising systematically, here is a concrete starting point.
Start measuring the four DORA metrics today. You do not need a sophisticated platform to begin. Deployment frequency can be tracked manually in a spreadsheet. Lead time can be measured from your version control timestamps. Mean time to recovery can be logged from your incident records. Change failure rate can be calculated from your deployment history. The act of measuring — even imprecisely at first — changes how the team thinks about the delivery process.
Pick one bottleneck and address it. Review your pipeline end to end and identify the single step that causes the most delay, the most failures, or the most manual intervention. Address that one thing. Measure the impact. Then find the next bottleneck. This is how optimisation compounds.
Make the pipeline a team responsibility. Hold a session where the entire team walks through the delivery process together — from code commit to production deployment. Make sure everyone understands every step. Invite everyone to identify problems and propose improvements. Distribute ownership.
Build a blameless incident review practice. Every production incident is a learning opportunity. Review what happened, why it happened, and what changes to the system would prevent it. Focus on systemic causes rather than individual mistakes. The output should be specific improvements to the delivery process, not individual accountability.
Final thought
The teams that get DevOps right are not the teams that automated the most. They are the teams that understood automation as the beginning of a longer journey — toward measurement, toward continuous improvement, toward a delivery system that gets better every week because the team is actively making it better.
The pipeline is not the product. The ability to deliver reliably, recover quickly, and improve continuously — that is the product. And building that capability is work that never fully stops.
The most mature DevOps teams are not the ones who have nothing left to improve. They are the ones who are best at finding and fixing the next thing.
Where is your team on this maturity curve right now? What is the single biggest obstacle between where you are and where you want to be? Share it in the comments.
References & Further Reading
For deeper reading on the ideas covered in this article, these resources are worth your time:



