Introduction: Reliable Systems Are Not Error-Free Systems
One of the most common misconceptions in software development is the belief that reliable systems are systems that never fail. In reality, every production-grade application experiences failures at some point. APIs become unavailable, databases slow down, queues stop processing correctly, and unexpected user behavior creates edge cases developers never predicted.
The difference between fragile systems and reliable systems is not the absence of errors — it is the ability to handle failures intelligently without causing widespread disruption.
Modern systems are built in environments where uncertainty is normal. Applications depend on:
- Third-party APIs
- Cloud infrastructure
- Distributed services
- External integrations
- User-generated input
Each dependency introduces new failure possibilities. If systems are designed only for “successful scenarios,” even small disruptions can create major outages.
This is why error handling should never be treated as an afterthought added near deployment. It is a core architectural responsibility that directly affects:
- Stability
- Scalability
- Maintainability
- User experience
- Operational reliability
Reliable systems assume failures will happen and prepare for them in advance.
Why Error Handling Is Often Undervalued
Many teams prioritize feature delivery because visible functionality is easier to measure. Clients notice new dashboards, APIs, or interfaces much faster than they notice strong failure handling behind the scenes.
As a result, development cycles often focus heavily on:
- Features
- UI improvements
- Performance optimization
- Delivery deadlines
While error handling receives minimal planning.
The problem with this approach is that systems rarely fail during ideal conditions. Failures appear under stress:
- High traffic
- Slow network conditions
- Unexpected inputs
- Infrastructure instability
- Third-party service interruptions
A feature may look perfect during testing but collapse under real production pressure if error handling is weak.
This creates systems where:
- Failures become difficult to trace
- Recovery becomes inconsistent
- Minor issues spread quickly
- Teams spend more time firefighting than improving systems
Strong engineering teams understand that error handling is not “extra work.”
It is what makes production systems survivable.
The First Principle: Fail Gracefully, Not Catastrophically
One of the most important principles in reliable architecture is graceful degradation. This means systems should continue functioning as much as possible even when some components fail.
Poorly designed systems often behave like tightly connected chains:
- One service fails
- Multiple dependencies stop working
- Users lose access completely
Reliable systems are designed differently. They isolate failures and reduce the impact radius.
For example:
- If analytics tracking fails, checkout should still work
- If recommendation engines stop responding, users should still browse products
- If notifications fail temporarily, core account functionality should remain available
This approach protects critical workflows instead of allowing secondary failures to destroy the entire experience.
Graceful failure handling usually involves:
- Service isolation
- Fallback mechanisms
- Temporary degraded functionality
- Controlled failure responses
The goal is not perfect operation under every condition.
The goal is controlled behavior during instability.
Use Structured Error Classification
Many unstable systems treat every error the same way. This creates confusion because different failures require completely different responses.
For example:
- Invalid user input is not the same as database corruption
- API timeout errors are not the same as authentication failures
- Network instability is not the same as application bugs
Without structured classification:
- Logs become noisy
- Debugging slows down
- Monitoring becomes unreliable
- Teams struggle to prioritize incidents
Reliable systems organize failures into clear categories such as:
- Validation errors
- Authentication failures
- Authorization errors
- Network timeouts
- Database failures
- External API issues
- Internal system exceptions
This improves operational clarity because each error type can trigger different handling behavior.
For example:
- Validation errors may return user guidance
- Timeout errors may trigger retries
- Database failures may activate fallback systems
Classification transforms error handling from reactive chaos into structured system behavior.
Defensive Programming Improves Stability
Defensive programming is the practice of designing systems that expect misuse, unexpected conditions, and imperfect environments.
Many unstable systems are built on assumptions like:
- APIs always return valid data
- Users always behave correctly
- Services always remain online
- Inputs always match expectations
Production systems quickly prove these assumptions wrong.
Reliable applications assume failures can occur at any point. Because of this, developers proactively build protections around critical operations.
Defensive programming often includes:
- Input validation
- Null checking
- Boundary testing
- Safe fallback values
- Exception handling safeguards
For example:
A payment API may unexpectedly return incomplete data. Without defensive validation, this can break downstream processing and create larger failures.
With defensive programming:
- The invalid response is detected early
- The failure is isolated safely
- Logging captures the issue clearly
- The system remains stable
This approach dramatically improves reliability because systems become resilient against unpredictable behavior instead of depending on ideal conditions.
Centralized Error Logging Is Essential
One of the biggest operational problems in software systems is lack of visibility. Teams cannot fix what they cannot clearly observe.
Without centralized logging:
- Errors become scattered
- Debugging consumes excessive time
- Production incidents become harder to trace
- Root causes remain unclear
Many teams initially rely on manual debugging or local server logs, but this approach becomes unsustainable as systems grow.
Reliable architectures use centralized logging systems that collect:
- Application exceptions
- Stack traces
- API request failures
- Queue processing errors
- Infrastructure warnings
- Performance anomalies
Centralized logging improves:
- Incident response speed
- Historical analysis
- Monitoring accuracy
- Cross-service debugging
More importantly, good logging provides context, not just error messages.
Instead of:
- “Request failed”
Reliable logs explain:
- Which request failed
- Why it failed
- Which service triggered it
- Which dependency was involved
- What conditions existed at the time
Visibility is one of the foundations of operational reliability.
Meaningful Error Messages Matter
Error messages affect both users and development teams far more than many systems designers realize.
Poorly written error messages create frustration because they provide no useful direction:
- “Something went wrong”
- “Unknown error”
- Generic server failure messages
These messages help neither users nor developers.
Reliable systems separate user-facing communication from internal technical diagnostics.
For users:
- Messages should remain clear and understandable
- Instructions should reduce confusion
- Sensitive system information should remain hidden
For developers:
- Logs should contain detailed debugging information
- Technical traces should remain internally accessible
Good error messaging improves:
- User trust
- Support efficiency
- Debugging speed
- Security protection
A well-designed error response helps users recover while helping developers investigate effectively.
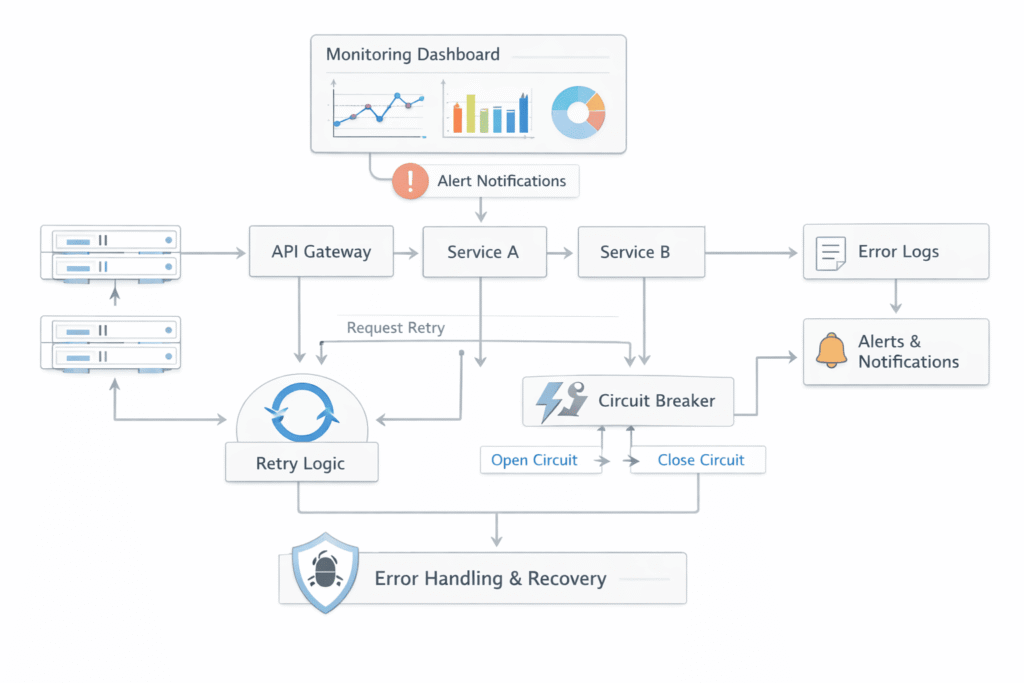
Retry Mechanisms Must Be Controlled
Retries are extremely useful in distributed systems because many failures are temporary. APIs may briefly slow down, databases may momentarily lose connections, or cloud services may experience short interruptions.
Retry mechanisms allow systems to recover automatically without immediate manual intervention.
However, retries become dangerous when implemented carelessly.
An unstable retry strategy can:
- Overload struggling services
- Increase infrastructure pressure
- Trigger cascading failures
- Waste system resources
For example:
If thousands of failed requests retry instantly at the same time, the already overloaded service becomes even less stable.
Reliable retry systems use controlled strategies such as:
- Retry limits
- Exponential backoff
- Delay intervals
- Failure thresholds
These mechanisms reduce system stress while still allowing temporary recovery opportunities.
Retries should always be intentional and monitored carefully.
Automatic retries everywhere often create more instability instead of resilience.
Circuit Breakers Prevent Cascading Failures
Distributed architectures introduce dependency risks because services continuously communicate with each other.
Without protection mechanisms:
- One failing service affects dependent services
- Request queues grow rapidly
- System resources become exhausted
- Entire environments become unstable
Circuit breakers solve this by temporarily stopping requests to repeatedly failing services.
Instead of endlessly retrying doomed operations, the system:
- Detects repeated failures
- Opens the circuit temporarily
- Prevents additional load
- Allows recovery time
This protects:
- Infrastructure resources
- Dependent systems
- Overall platform stability
Circuit breakers are especially valuable in:
- Microservices architectures
- External API integrations
- Cloud-native systems
- High-traffic distributed environments
This pattern limits failure spread and improves recovery control significantly.
Monitoring and Alerting Are Part of Error Handling
Many teams think error handling only starts after failures happen. In reality, strong reliability engineering focuses heavily on early detection.
Monitoring systems continuously track:
- Error rates
- Service health
- Response times
- Queue delays
- Resource usage
- Infrastructure anomalies
This allows teams to identify degradation before major outages occur.
For example:
- Rising response times may indicate infrastructure stress
- Increased timeout rates may signal API instability
- Growing queue sizes may reveal processing bottlenecks
Alerting systems then notify teams when thresholds are exceeded.
Without monitoring:
- Problems remain invisible
- Recovery becomes reactive
- Small failures quietly grow into major incidents
Reliable systems depend heavily on operational awareness, not just code quality.
Error Handling in Asynchronous Systems Requires Extra Care
Asynchronous systems improve scalability and responsiveness, but they also introduce additional reliability complexity.
Unlike synchronous requests, asynchronous failures may occur silently in background processing systems.
Examples include:
- Failed queue jobs
- Delayed event processing
- Duplicate message execution
- Background task crashes
Without visibility, these failures may remain unnoticed for long periods.
Reliable asynchronous architectures use:
- Queue monitoring
- Dead-letter queues
- Retry management
- Failure tracking systems
- Idempotent operations
These mechanisms ensure failed jobs are:
- Captured properly
- Investigated safely
- Retried carefully
- Prevented from causing duplication issues
Asynchronous reliability depends heavily on operational observability because failures are often less visible to users initially.
Never Expose Internal System Details to Users
One of the most common mistakes in application error handling is exposing raw internal errors directly to users.
Examples include:
- Stack traces
- SQL queries
- File paths
- Internal server details
This creates both:
- Security risks
- Poor user experiences
Attackers can use exposed system information to better understand infrastructure weaknesses.
Reliable systems separate:
- Internal technical diagnostics
From: - Public-facing communication
Users should receive:
- Clear explanations
- Actionable next steps
- Safe failure messaging
While developers retain:
- Detailed logs
- Debugging traces
- Technical diagnostics internally
This balance improves security without sacrificing usability.
Testing Failure Scenarios Improves Reliability
Many systems are tested primarily for successful outcomes. But production reliability depends far more on how systems behave during failure conditions.
Reliable engineering teams intentionally simulate:
- API outages
- Database failures
- Timeout scenarios
- Queue overload
- Network instability
- Invalid user input
This process reveals weaknesses before production incidents occur.
Failure testing improves:
- Recovery confidence
- Operational preparedness
- System resilience
- Team response coordination
Reliable systems are not only designed for ideal situations.
They are stress-tested for instability and unexpected behavior.
Documentation Reduces Error Recovery Time
During production incidents, missing documentation creates confusion very quickly.
Teams may struggle to understand:
- Recovery procedures
- Service dependencies
- Retry behavior
- Escalation processes
- Failure ownership
Reliable systems maintain documentation for:
- Error handling workflows
- Recovery procedures
- Monitoring rules
- Alerting thresholds
- Operational dependencies
This improves:
- Incident response speed
- Team coordination
- Maintenance consistency
- Knowledge sharing across teams
Good documentation transforms operational reliability from individual memory into organizational process.
Key Takeaways
- Reliable systems assume failures will happen
- Error handling is part of architecture, not just debugging
- Structured classification improves recovery behavior
- Defensive programming reduces instability
- Monitoring and logging improve operational visibility
- Controlled retries and circuit breakers prevent cascading failures
- Failure testing strengthens long-term system reliability
Conclusion: Reliability Comes from Preparedness, Not Perfection
No software system operates forever without failures.
Servers become unstable.
Dependencies fail.
Traffic patterns change.
Unexpected edge cases emerge constantly.
What separates reliable systems from fragile systems is preparation.
Strong error handling strategies allow applications to:
- Recover gracefully
- Minimize operational damage
- Protect user experience
- Improve long-term maintainability
Modern software reliability is not built by pretending errors won’t happen.
It is built by designing systems that continue functioning intelligently when they do.
Because ultimately,
system reliability is not about avoiding failures — it’s about controlling their impact before they spread.
References:
- Microsoft – Error Handling Patterns
https://learn.microsoft.com/en-us/azure/architecture/patterns/category/resiliency - Amazon Web Services – Building Resilient Systems
https://aws.amazon.com/builders-library/ - Google Cloud – Site Reliability Engineering Principles
https://sre.google/sre-book/table-of-contents/ - Atlassian – Incident Management Guide
https://www.atlassian.com/incident-management - IBM – Error Handling Best Practices
https://www.ibm.com/docs/en/was/9.0.5?topic=applications-exception-handling-best-practices



