Introduction
A feature works perfectly on a developer’s machine—but fails in production.
This is one of the most common and costly problems in modern software delivery. Not because developers lack skill, but because the path from code to deployment is fragile, inconsistent, or poorly designed.
In today’s systems, reliability is no longer just about writing clean code. It is about building a delivery pipeline that ensures every change moves safely, predictably, and efficiently into production.
A reliable delivery pipeline is not a luxury—it is a core business capability. It determines how fast you can ship, how confidently you can release, and how quickly you can recover when something breaks.
Concept Foundation
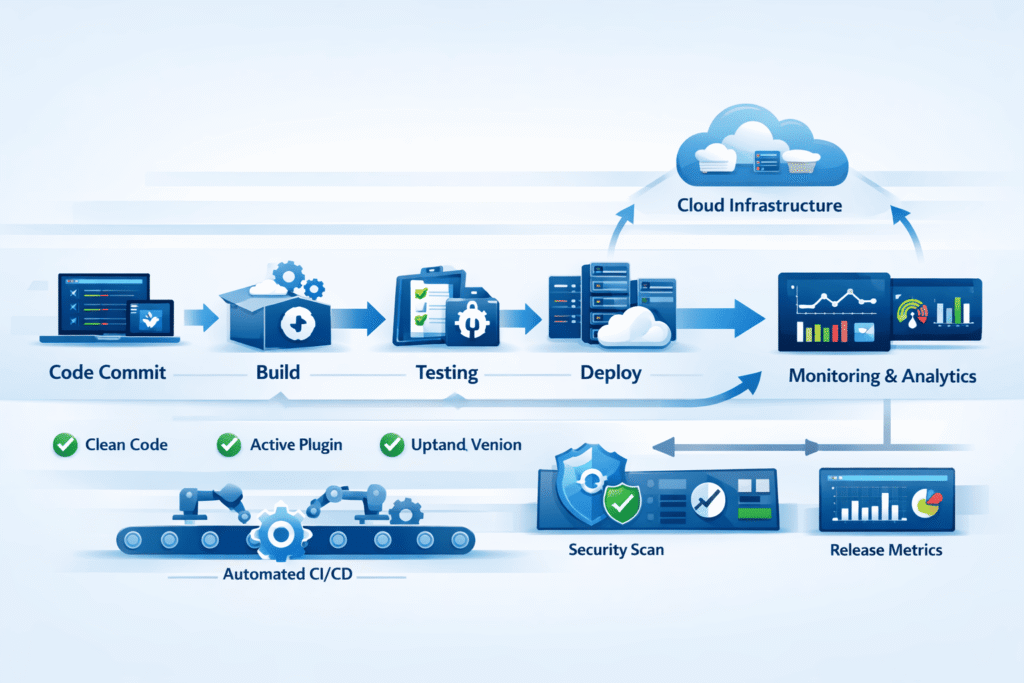
A delivery pipeline is the automated process that takes code from version control and moves it through stages such as:
- Build
- Testing
- Integration
- Deployment
At its core, it connects development → validation → release into a continuous, repeatable workflow.
Modern delivery pipelines are built on principles like:
- Automation over manual steps
- Consistency across environments
- Early detection of failures
- Fast feedback loops
Without these, teams rely on manual deployments, inconsistent environments, and delayed testing—leading to failures that only appear in production.
How the Problem Occurs
Most unreliable pipelines are not designed—they evolve unintentionally.
Common root causes include:
- Manual deployment steps that vary per release
- Lack of environment parity (dev ≠ staging ≠ production)
- Incomplete or slow testing processes
- No rollback or recovery strategy
- Tight coupling between components
These issues create a system where:
- Bugs are discovered late
- Releases become stressful events
- Teams avoid deploying frequently
- Small changes carry high risk
Over time, delivery slows down—not because of code complexity, but because of pipeline instability.
1. The Foundation: Version Control as the Single Source of Truth
Everything in a reliable pipeline starts with version control.
This includes not just application code, but also:
- Infrastructure configurations
- Deployment scripts
- Environment settings
A strong pipeline treats the repository as the single source of truth, ensuring that any environment can be recreated from it.
Key practices:
- Use structured branching strategies (e.g., trunk-based or GitFlow)
- Enforce pull requests and code reviews
- Maintain clean commit history
Without this discipline, pipelines become unpredictable because the input itself is inconsistent.
2. Automated Build and Dependency Management
A reliable pipeline begins with a repeatable build process.
Every commit should trigger:
- Dependency installation
- Compilation (if applicable)
- Artifact generation
The goal is simple:
If it builds once, it should build the same way every time.
Key considerations:
- Lock dependency versions to avoid unexpected updates
- Use containerized builds for consistency
- Generate immutable artifacts (e.g., Docker images)
When builds are inconsistent, deployments become unreliable—even before testing begins.
3. Testing Strategy: Shift Left for Reliability
Testing is not a stage—it is a continuous safety mechanism.
A strong pipeline includes multiple layers:
- Unit tests (fast, isolated)
- Integration tests (component interaction)
- End-to-end tests (real workflows)
The key principle is shift-left testing:
Detect issues as early as possible in the pipeline.
Why this matters:
- Fixing a bug in development is cheap
- Fixing it in production is expensive
Best practices:
- Fail fast—stop the pipeline on critical test failures
- Keep tests deterministic and reliable
- Avoid over-reliance on slow end-to-end tests
4. Environment Consistency and Infrastructure as Code
One of the biggest causes of deployment failure is:
“It worked in staging, but not in production.”
This happens when environments are configured differently.
The solution is Infrastructure as Code (IaC).
Instead of manually configuring servers, define environments using code:
- Server configurations
- Networking rules
- Scaling policies
Benefits:
- Reproducibility across environments
- Reduced configuration drift
- Easier debugging and rollback
Combined with containerization (e.g., Docker), this ensures that applications behave consistently from development to production.
5. Continuous Integration: Small Changes, Fast Feedback
Continuous Integration (CI) ensures that:
- Code changes are integrated frequently
- Each change is validated automatically
Instead of large, risky releases, teams work with small, incremental updates.
Pipeline flow in CI:
- Developer pushes code
- Pipeline triggers automatically
- Build + tests run
- Feedback is provided within minutes
Impact:
- Faster detection of issues
- Reduced merge conflicts
- Increased confidence in code changes
Without CI, integration becomes a bottleneck—and failures accumulate silently.
6. Continuous Deployment: Reducing Release Risk
Continuous Deployment (CD) takes CI further by automating releases.
Once code passes all checks, it can be:
- Deployed to staging automatically
- Promoted to production with minimal manual intervention
Advanced deployment strategies:
- Blue-Green Deployment – Switch traffic between environments
- Canary Releases – Gradually expose changes to users
- Rolling Updates – Update services incrementally
These approaches reduce risk by avoiding “all-at-once” deployments.
7. Monitoring, Logging, and Feedback Loops
A pipeline does not end at deployment.
Reliability depends on what happens after release.
Key components:
- Monitoring – Track system health and performance
- Logging – Capture detailed system behavior
- Alerts – Detect anomalies in real time
Why this matters:
- Not all issues can be caught in testing
- Production visibility enables faster recovery
A strong feedback loop ensures that:
- Issues are detected quickly
- Teams can respond before users are impacted
8. Rollback and Recovery Strategies
Even the best pipelines cannot prevent every failure.
What defines reliability is:
How quickly and safely you can recover.
Every pipeline should include:
- Automated rollback mechanisms
- Versioned deployments
- Database migration strategies with backward compatibility
Example approach:
- Keep previous stable versions ready
- Switch traffic back instantly if needed
Without a rollback plan, every deployment becomes a high-risk operation.
Practical Implementation
To build a reliable delivery pipeline, follow a structured approach:
Step 1: Standardize Version Control
- Central repository
- Enforced review process
Step 2: Automate Build Process
- Use tools like Jenkins, GitHub Actions, or GitLab CI
- Create reproducible build environments
Step 3: Implement Layered Testing
- Start with unit tests
- Gradually add integration and E2E tests
Step 4: Introduce CI/CD Pipelines
- Automate validation on every commit
- Enable staged deployments
Step 5: Use Infrastructure as Code
- Tools like Terraform or CloudFormation
- Ensure environment consistency
Step 6: Add Monitoring and Alerts
- Track performance and errors
- Create actionable alert systems
Step 7: Plan for Failure
- Design rollback strategies
- Test recovery processes regularly
Common Mistakes
1. Treating deployment as a manual process
Manual steps introduce inconsistency and human error.
Better approach: Fully automate repeatable processes.
2. Ignoring environment differences
Different configurations lead to unpredictable failures.
Better approach: Use containers and IaC for consistency.
3. Overloading pipelines with slow tests
Slow pipelines discourage frequent deployments.
Better approach: Balance speed and coverage.
4. No rollback strategy
Without recovery, even small failures become critical incidents.
Better approach: Design rollback from day one.
5. Large, infrequent releases
Big changes increase risk and complexity.
Better approach: Ship small, frequent updates.
Key Takeaways
- Reliable delivery pipelines are system design problems, not tooling problems
- Automation is essential for consistency and scalability
- Early testing reduces long-term risk and cost
- Environment parity prevents deployment surprises
- Continuous integration enables faster, safer development
- Recovery strategies are as important as deployment strategies
Conclusion
From code to deployment, reliability is built—not assumed.
A well-designed delivery pipeline transforms software delivery from a risky, manual process into a predictable, scalable system.
It allows teams to:
- Ship faster without fear
- Detect issues earlier
- Recover quickly when failures occur
In modern development, the question is no longer:
“Can we deploy?”
But rather:
“Can we deploy confidently, repeatedly, and at scale?”
That confidence comes from building pipelines that are not just functional—but intentionally designed for reliability.



